Background: In this series of posts, I’ve been using medical device development (as Regulated by U.S. FDA via CFR 820.30 and international standard IEC62304) as an exemplar for suggesting ways to develop high quality software in regulated (and other high assurance, high economic cost of failure) environments in an agile manner. This series is sponsored, in part, by Rally Software Development, with special thanks to Craig Langenfeld for his ongoing contribution.
====================================
As we described in earlier posts, verification occurs continuously during the course of each iteration. Validation also occurs on a cadence, (see post) primarily in the course of special iterations dedicated to this purpose. This is the third in a series of verification posts, covering the testing of the features found in the PRD.
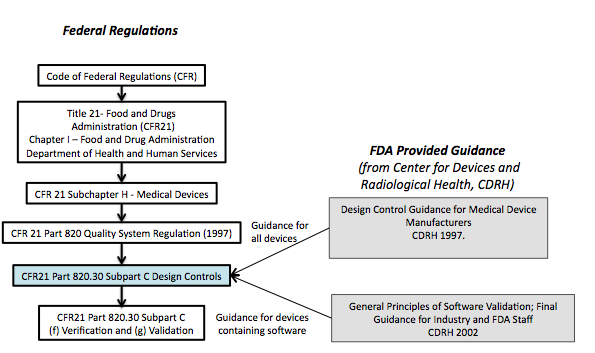
In the last post, we described the Product Requirements Document as the higher level (superordinate to the SRS) governing document for our device or system. Its content includes the purpose of the device, as well as a set of features and nonfunctional requirements that describe the behavior of the system at a fairly high level. As I described in Agile Software Requirements, features are primary elements of the agile requirements metamodel, as the graphic below illustrates:

Features in the requirements metamodel
Since features are implemented by stories, and we have described a pretty thorough job of testing those:

Stories are unit and acceptance tested
the question arises as to whether or not features must be independently tested as well. As implied by the model, the answer is yes. This is a key part of our verification strategy as “software verification provides objective evidence that the design outputs of a particular phase of the software development life cycle meet all of the specified requirements for that phase”. While an argument can be made that this is accomplished solely through story testing as the stories were derived from the features, the facts are often otherwise:
- It can take a large number of stories to implement a single feature. Even if they all deliver value, most stories do not stand alone.
- There are a large number of paths through the stories, which cannot be naturally tested by the independent story acceptance tests.
- In systems of scale and complexity, features often require full system integration with other systems components and features, and in many cases a single team may not be even able to access the resources necessary to fully test the feature they contributed to.
For these reasons, we have indicated a separate Feature Acceptance Test in the requirements model.
Each time a new feature from the PRD is implemented by the team, in addition to the story implementations and story tests, a FAT must typically be developed and persisted by the team in the system level regression test repository. Whenever these tests are automated (typically with some business logic-level, FIT-like (Framework for Integrated Tests) custom framework, the FATs can be executed continuously in the course of each iteration. Where automation is not possible, then these tests tend to build overhead that must be executed, at least, at each system increment. Often this latter effort becomes a part of the formal validation process, which, as we have described, typically occurs in special hardening sprints dedicated to that and similar purposes. As feature testing is continuous, it is integral to verification and mitigates late discovery of changes which cause defects. Running the full set of feature regression tests, including all manual tests, is an integral part of our system validation process.
Conclusion
For the moment, that’s it for the verification discussion. However, in a like manner to features, the teams will also need to address the nonfunctional requirements for the system and they get handled a little but differently. That will be the subject of the next post in the series.






{kind=link}